Timp de aproape cinci ani, industria inteligenței artificiale a fost dominată de o singură obsesie: antrenarea modelelor de limbaj de mari dimensiuni.
Procesul este costisitor, consumă cantități uriașe de energie și se desfășoară în centre de date gigantice, unde mii de cipuri specializate rulează neîntrerupt, săptămâni sau luni întregi, asimilând miliarde de informații — de la definiții de cuvinte și fapte istorice până la statistici financiare și imagini. Acum, însă, centrul de greutate al sectorului se mută vizibil spre un alt tip de procesare: inferența.
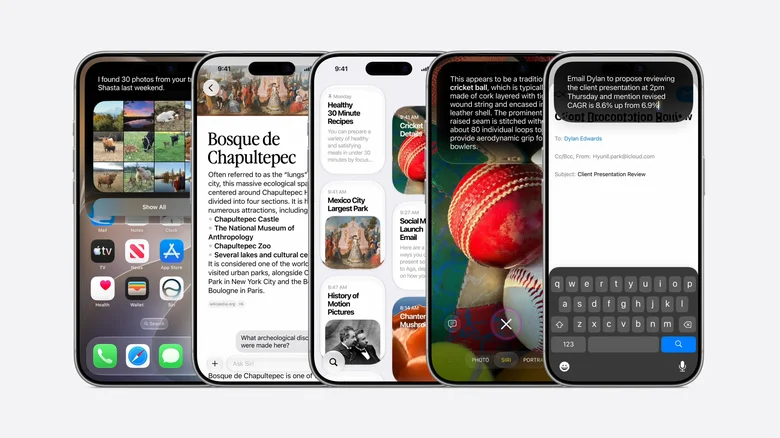
Inferența este ceea ce se întâmplă după antrenare — momentul în care un model AI deja pregătit răspunde efectiv la întrebările utilizatorilor. Dacă antrenarea poate fi comparată cu formarea unui chef care învață sute de rețete și tehnici, inferența reprezintă operațiunea zilnică a restaurantului: clienții plasează comenzi, iar bucătarul le pregătește. Această distincție, aparent tehnică, are acum implicații majore pentru întreaga industrie.
Potrivit firmei de cercetare Gartner, cheltuielile globale pentru servicii cloud de înaltă performanță dedicate inferenței AI vor depăși pentru prima dată, în acest an, cheltuielile similare destinate antrenării modelelor. Până în 2029, companiile vor cheltui aproape dublu pe infrastructura de inferență față de cea de antrenare — 72 de miliarde de dolari, comparativ cu 37 de miliarde.
Această schimbare antrenează, la rândul ei, o reconfigurare a pieței cipurilor. Nvidia a devenit cea mai valoroasă companie din lume vânzând procesoare grafice (GPU-uri) cu putere brută de calcul, ideale pentru antrenarea modelelor.

Inferența are însă cerințe diferite: procesul se desfășoară la cerere, în câteva secunde, nu în săptămâni, și impune cipuri cu cantități mai mari de memorie de mare viteză, amplasate în centre de date plasate cât mai aproape de utilizatori pentru a reduce latența. Jacob Feldgoise, cercetător în domeniul AI la Universitatea Georgetown, subliniază că performanțele pot fi îmbunătățite semnificativ prin utilizarea unor cipuri specializate pentru inferență.
Tehnic, inferența se desfășoară în două faze distincte. Prima, numită prefill, are loc atunci când utilizatorul introduce o interogare, iar modelul procesează fiecare cuvânt, simbol sau imagine din aceasta. A doua fază, decode, reprezintă generarea propriu-zisă a răspunsului — modelul produce câte un token pe rând, în ordinea corectă.
Un token echivalează, în linii mari, cu aproximativ trei sferturi dintr-un cuvânt în limba engleză; o întrebare simplă de tipul „Cum va fi vremea azi?” este interpretată ca șase până la opt tokeni. Prefill solicită mai multă putere de procesare, în timp ce decode depinde în mai mare măsură de memorie.
Tocmai de aceea, companiile care încearcă să monetizeze instrumente AI — de la software de contabilitate la servicii de rezervări sau generatoare de imagini — urmăresc cu atenție indicatori precum tokeni pe secundă per watt sau tokeni pe secundă per dolar.
„Reducerea costului inferenței este acum numele jocului”, spune Tim Breen, directorul executiv al GlobalFoundries. Rodrigo Liang, CEO al firmei de design de cipuri SambaNova, adaugă că răbdarea utilizatorilor este limitată: „Zece secunde și oamenii deja bat cu degetele în telefon, gata să treacă mai departe.”
Pe acest fond, producătorii de cipuri optimizate pentru inferență — printre care Google, Cerebras Systems și SambaNova — semnează contracte de miliarde de dolari într-un ritm accelerat. Nvidia, la rândul său, nu stă deoparte: compania urmează să lanseze procesoare dedicate inferenței, după ce în decembrie a plătit 20 de miliarde de dolari pentru a licenția tehnologia și a prelua talentele de top de la Groq, o firmă specializată în cipuri pentru inferență.
Inferența AI depășește antrenarea ca prioritate de investiții. Aflați ce înseamnă această schimbare pentru cipuri, centre de date și piața tehnologică.Startup-uri precum Ayar Labs merg și mai departe, conectând componente prin fibră optică — mai rapidă decât cablajul de cupru și cu cerințe mai reduse de răcire. „Totul se concentrează astăzi pe scalarea inferenței”, rezumă Mark Wade, CEO-ul Ayar Labs.
Industria AI intră astfel într-o nouă fază de maturitate, în care contează mai puțin cât de mare și de puternic este un model, și mai mult cât de eficient și de rapid poate fi acesta în interacțiunea cu milioane de utilizatori simultan.